In the past 24 hours the AI world didn’t just see a few new model releases. On the surface there were three updates:
- Qwen 3.6-Max-Preview released
- Kimi K 2.6 released
- Claude added “live artifacts” in Cowork
If you treat each item as a simple news item, that’s fine. But viewed together they reveal a deeper shift. Today’s large-model competition looks less like a chat-bot contest and more like two parallel fronts advancing at once:
- The model-layer front: which model can run agentic coding better, execute long-running tasks, handle multi-file projects, tool calls, and complex development flows.
- The product-layer front: which team can turn a model into a ready-to-use work system that displaces the value once supported by software seat licensing.
1. Qwen 3.6-Max-Preview: not just an update, but a push toward agentic coding
Tongyi Lab’s announcement used clear keywords: “agentic coding,” “stronger world knowledge,” and “real-world reliability.” The important point is the focus on developer workflows.

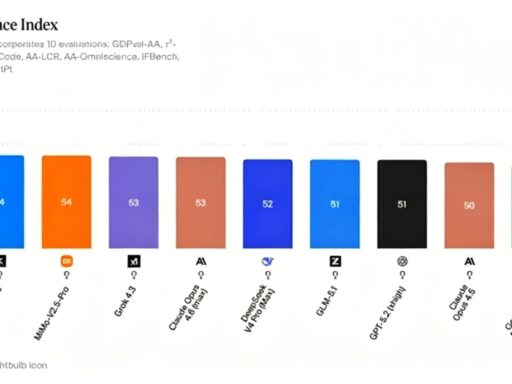
High-value model competition today isn’t about who sounds better in chat. It’s about which model can keep running reliably through complex tasks. The benchmark chart they released carries information, but the real signal is stance: Qwen is now aiming at high-intensity coding and agent tasks, not ordinary chat leaderboards.
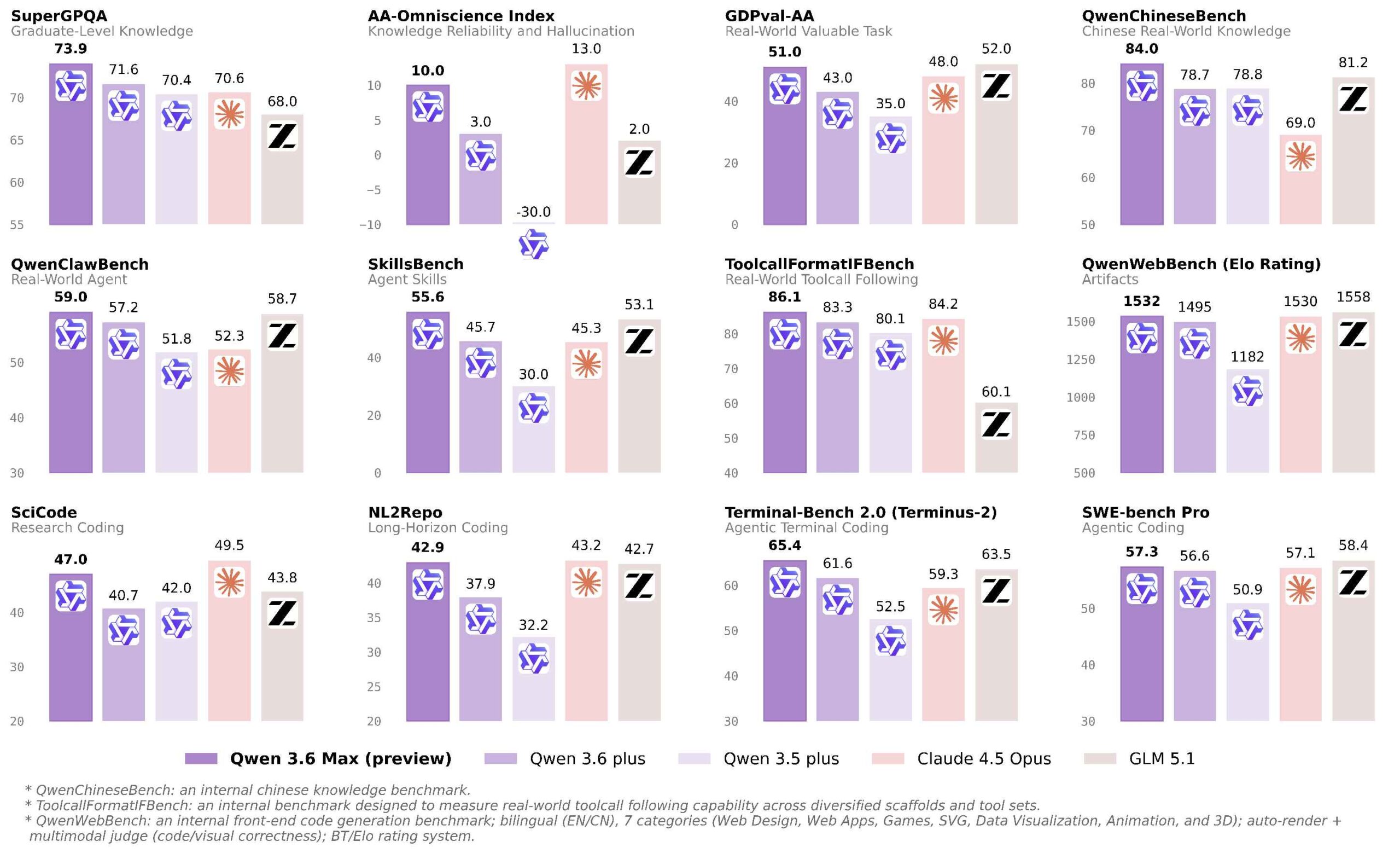
Do note the word “Preview.” This release signals direction, not necessarily final stability.
2. Kimi K 2.6: more like an outward attack than a slow approach
Compared with Qwen’s steady push, Kimi K 2.6 feels more aggressive. Kimi’s team frames the release as “Advancing Open-Source Coding.” Their narrative is concrete:
- Long-running coding with 4,000+ tool calls and continuous execution beyond 12 hours
- Motion-rich frontend generation
- Support for 300 parallel sub-agents
- Proactive agents and research previews of “Claw Groups”
This is not a single-capability upgrade. It’s building toward a full agent runtime for coding. That makes Kimi’s move dangerous for incumbents: it targets not just the model slot but an entire coding product stack.

Practical tests reinforce this: Kimi has already been plugged into agent frameworks and run in real tests. Benchmarks are useful, but real-world integration into agent systems is far more convincing.
3. It’s too early to say Chinese models fully replace Opus, Codex, or GPT-5.4
It’s tempting to declare that Chinese AI models have fully replaced top-tier closed models. From the last 24 hours, that claim is too strong.
A more accurate view: in key tasks—coding, frontend generation, tool use, and agent workflows—replacement is already starting to happen. But “complete replacement” has not yet occurred.
Three reasons:
- Qwen 3.6 is labeled a “Preview,” not a finished, stable release.
- Even with strong feedback for Kimi K 2.6, opinions inside China vary—some say it’s only slightly better than Kimi 2.5 and still behind alternatives like GLM 5 in some respects.
- Top closed models are hard to replace because their edge is not just peak benchmark scores, but long-time stability, project consistency, fault tolerance under edge conditions, and the integrated product experience built around them.
So: Chinese models have entered a high-value replacement zone and are taking concrete, real tasks away from Claude/Codex/GPT-5.4, but the job is not done.
4. Claude live artifacts: Anthropic still excels at turning model power into industry impact
If Qwen and Kimi are model-layer offensives, Claude’s live artifacts are a precise product-layer strike. Anthropic quietly described that in Cowork, Claude can now build live artifacts—dashboards and trackers that connect to apps and documents and refresh with current data.
They added that these artifacts are saved in a new “Live Artifacts” tab with version history. That changes everything: these are not one-off demos or static dashboards. They become living objects that connect data, refresh over time, and keep a version trail.
Where does this hit? Business intelligence, internal tools, dashboard builders, and lightweight workbenches—software categories that have historically charged seat fees for packaging complex data work. Live artifacts directly undercut that model.
5. The main trend in the last 24 hours: models moving up while software value moves down
Compressed into one judgment:
Chinese AI models are pushing the capability threshold down from the top, while Claude is pulling traditional software value down by turning model outputs into persistent, connected work objects.
Consequences:
- It becomes harder for high-priced capabilities (Opus, Codex, GPT-5.4) to keep their mystique.
- Software that relied on UI packaging and seat fees will find parts of its value contested by model-based work systems.
So the real story isn’t “three new features.” It’s two deeper shifts:
- Chinese AI models have moved into the main coding battlefield—they’re not an outside variable anymore, they’re front-line competitors.
- Competition at the application layer now looks like a step-by-step dismantling of SaaS vertical categories.
Conclusion
In the space of 24 hours, we saw signals on both fronts: model capabilities tightening around agentic, long-running coding tasks, and product teams turning models into persistent, versioned tools that can replace traditional software value. Watch both fronts: the technical advances will keep accelerating, and the product plays will determine who actually captures long-term business value.