In late October 2025, the large model community witnessed a theatrical showdown. MiniMax released its M2 model with 230 billion parameters, surprisingly abandoning its previously heavily promoted “Lightning Attention” in favor of the most traditional Full Attention mechanism. Sun Haohai, head of pre-training, wrote a candid technical blog: “We’ve been working on linear attention, but in industrial systems, it still has some distance to go before it can truly beat Full Attention.” Within 72 hours, Zhou Xinyu, a researcher at Moonshot AI, reposted the M2 announcement on X with a cryptic comment: “MiniMax don’t worry, Kimi got your back.” The next day, Kimi Linear was unveiled—a 48B parameter hybrid attention model claiming to be the first to comprehensively surpass full attention in fair comparisons, slashing KV cache by 75% and boosting million-token decoding throughput by 6x. One said, “Linear attention isn’t mature enough yet, so I’m pulling back,” while the other declared, “I’ll do what you dare not.” In just 72 hours, two Chinese AI companies engaged in a textbook-level technical debate over this fundamental component: the attention mechanism.
Six months later (April 2026), the follow-up to this story becomes even more intriguing. MiniMax just open-sourced M2.7, officially defined as “the first large model deeply involved in its own evolution”—the model autonomously built an Agent Harness, driving reinforcement learning loops to complete 100 rounds of autonomous iteration. Meanwhile, DeepSeek V4 is poised to launch with a 1 trillion parameter MoE architecture and a brand-new Engram Memory conditional memory system. Alibaba’s Qwen 3.5 was released on New Year’s Eve, a 397 billion parameter natively multimodal model with inference throughput improved by 19x. The landscape is far more complex than six months ago. But this has also brought a deeper question to the surface.
Looking back over these six months, the pace of model iteration has become dizzying. MiniMax went from M1’s Lightning Attention, to M2’s return to Full Attention, to M2.7’s “model participating in its own evolution.” Kimi progressed from K2 to K2.5, continuously deepening its hybrid attention approach. Alibaba’s Qwen evolved from Qwen3-Max to the New Year’s Eve release of Qwen 3.5 Plus (397 billion parameter native multimodal), to Qwen3-Coder-Next (hybrid attention + MoE architecture, where the model learns programming directly from environmental feedback).
DeepSeek moved from V3/R1 to the upcoming V4—1 trillion parameter MoE with Engram Memory conditional memory and the mHC architecture. Zhipu’s GLM-5 entered the fray with 744B parameters. Google, while releasing Nested Learning and the HOPE architecture at NeurIPS 2025, open-sourced Gemma 4 in April 2026 (31B parameters matching 200B-level models). Sam Altman returned to his alma mater Stanford and told a group of sophomores: “In the future, there will definitely emerge a brand-new underlying architecture whose performance leap will be no less than the dimensional reduction strike that Transformer delivered against LSTM.”
Everyone is talking about architecture. Linear attention, SSM, Mamba, DeltaNet, diffusion models, world models… the terms grow increasingly grandiose. But Danijar Hafner, DeepMind’s world model researcher—the one behind the Dreamer series that lets AI “learn in imagination”—said something counterintuitive: “I think almost any architecture can get us to AGI. Transformers can, and so can RNNs. The difference is just computational efficiency and adaptation to current hardware.” At first glance, this sounds like hedging. But thinking deeper, he might be pointing to something more fundamental.
![]()
O(n²) Is Just a Symptom, Not the Root Cause
Transformer’s self-attention has O(n²) computational complexity—double the sequence length, quadruple the computation. When processing 1 million tokens, the KV cache alone consumes several gigabytes of VRAM. This has been discussed to death. O(n²) is, at best, a fever; the real infection lies elsewhere.
I tried to break down the deep problems facing Transformer and found they actually belong to three completely different layers, while most “alternative architectures” currently only operate at the shallowest layer.
First, the most obvious: inference is too expensive. Running inference on a GPT-5.4-level model consumes enough electricity to power an average household for months. NVIDIA’s stock has soared because Transformers and GPUs are a perfect match. But this also means the entire industry is locked into one hardware path—chips are optimized for Transformers, making researchers even less willing to explore new architectures, creating a self-reinforcing cycle. This is an engineering problem with engineering solutions.
Then there’s one people don’t talk about much: learn and forget. You chatted with ChatGPT for an afternoon, reaching interesting conclusions. The next day, it knows nothing of your preferences or your discussions. Why? Because its parameters were frozen the moment pre-training ended. For it to “learn” new things, the only path is to collect more data, burn more electricity, and train a larger version from scratch. As Zhihu user “Fei Yi” aptly put it: “Language models can say many things, but they’ve never ‘touched the world.'” Human cognition updates daily—meeting new people, making new mistakes, quietly adjusting judgments. This process doesn’t require formatting your entire brain.
Google DeepMind’s Nested Learning, presented at NeurIPS 2025, targets this problem. The core idea is to have different model modules update at different frequencies—some learn fast but forget fast, others learn slow but remember long. Knowledge continuously flows between fast and slow modules. The HOPE architecture indeed beat existing baselines on long-context and continual learning tasks. But honestly, this is still far from large-scale engineering deployment.
The deepest problem hides in a seemingly mundane fact: Transformer only predicts the next token. The training objective is Next Token Prediction—guessing what word comes next. This objective has demonstrated astonishing linguistic capabilities and even some reasoning ability. But there’s a chasm between “fitting” and “reasoning.” As Zhihu user “Fusheng Yimeng” put it in mathematical language: Everything Transformer does is essentially interpolation on a high-dimensional manifold. For Out-of-Distribution problems beyond the training data distribution, interpolation fails. Chain-of-Thought is just a prompt engineering patch, not an architecture-level endogenous capability.
Sholto Douglas, head of Anthropic’s RL team, maintains an optimistic view that “we don’t need new architectures; reinforcement learning alone can bring Transformers to human expert levels.” But he admits a prerequisite—RL requires defining what constitutes “good performance.” Easy for coding (if it runs, it works), but how do you define it for writing articles? For business decisions?
These three layers of problems increase in importance but decrease in attention. O(n²) is visible to everyone, hence the endless stream of linear attention and sparse attention solutions. Continual learning is relatively niche, with only Google HOPE seriously addressing it. As for the deepest problem—”only capable of next-token prediction”—frankly, few are touching it.
![]()
What Are Those Alternative Architectures Actually Doing?
With this hierarchy clear, the heavily hyped alternatives become transparent.
Kimi Linear (October 2025): 3 KDA layers paired with 1 Full Attention layer, 75% reduction in KV cache, 6x improvement in decoding throughput. An efficiency-level improvement—beautiful. But the learning paradigm remains identical to the original Transformer: solidify after pre-training.
Qwen 3.5 Plus (February 2026): 397 billion parameters natively multimodal, only 17 billion activated, inference throughput up 19x. Gated attention mechanisms suppressed invalid attention from 46.7% to 4.8%. Efficiency pushed to the extreme, but essentially still “train then lock.”
Qwen3-Coder-Next (February 2026): This one is slightly different. Hybrid attention + MoE architecture, with training beginning to lean toward “learning from environmental feedback”—using large-scale verifiable programming tasks and executable environments, the model recovers directly from execution failures. This is starting to touch the second-layer problem.
DeepSeek V4 (April 2026, upcoming): 1 trillion parameter MoE, accompanied by three new architectural innovations: Engram Memory (conditional memory system), Manifold-constrained Hyper-Connections, and DeepSeek Sparse Attention. Engram Memory is particularly noteworthy—the name comes from the neuroscience concept of “memory engrams,” giving the model conditional memory retrieval capabilities. This is no longer mere efficiency optimization.
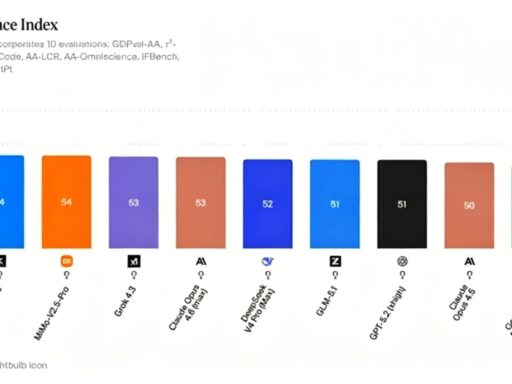
MiniMax M2.7 (March 2026 release, open-sourced April 13): The most surprising. Officially positioned as “the first large model deeply participating in its own evolution”—the model autonomously built an Agent Harness, driving RL loops to complete 100 rounds of autonomous iteration, with internal evaluations showing 30% overall improvement. SWE-Pro score of 56.22%, approaching Claude Opus 4.6. If this isn’t hype, then it has begun touching the third-layer problem—the model itself judges where it’s inadequate and fixes it.
Google HOPE: Nested learning allows the model to continuously absorb new knowledge without forgetting. Early academic work, but forms an interesting resonance with MiniMax M2.7’s approach.
Summarizing the New Landscape of 2026: The efficiency problem has been largely solved by all players (MoE, hybrid attention, gated attention). Continual learning is beginning to be addressed (Qwen3-Coder-Next, DeepSeek V4’s Engram Memory). As for transformation of the learning paradigm itself, MiniMax M2.7 may be the first to truly take this step—though still preliminary.
To use an imperfect analogy: Everyone is researching how to make the engine more fuel-efficient, but no one stops to ask: Should we be using a different mode of transportation altogether?
An Uncomfortable Reality
After all this talk of future directions, there’s an uncomfortable reality: For at least the next 3-5 years, Transformer will likely remain mainstream.
The reasons are plain. As of April 2026, the strongest models—DeepSeek V4 (1 trillion parameter MoE + Engram Memory), Qwen 3.5 Plus (native multimodal), GLM-5 (744B), Kimi K2.5, MiniMax M2.7, GPT-5.4, Gemini 3—are fundamentally still Transformers or their variants. The ecosystem, engineering accumulation, hardware adaptation, and talent pool are all on this side. It looks more like engineering optimization than a revolutionary improvement—like the transition from convolution to capsule networks, or MLP to complex-valued neural networks: grandiose names but landing like air.
However, several new movements in 2026—MiniMax M2.7’s autonomous iteration, DeepSeek V4’s Engram Memory—are at least attempting to touch deeper-level problems rather than just tweaking attention formulas. As one commentator put it bluntly: “Software engineers do this daily, yet these AI people have taken it and coined a new term.” Isn’t Harness Engineering just feedback control? Aren’t Agents just task orchestration? Concept fatigue is real. But concept fatigue doesn’t mean the direction is wrong. The problem is that the vast majority of “innovations” are indeed just engineering optimizations within the same paradigm, then packaged as paradigm revolutions to raise funding.