When DeepSeek released its V4 series in early 2026, the benchmarks looked promising—suspiciously promising, even. According to the company’s own reports, DeepSeek V4-Pro had achieved near-parity with OpenAI’s GPT-5.4 and Anthropic’s Claude Opus 4.5 across standard mathematical and coding evaluations. For a moment, it appeared that China’s large language model (LLM) ecosystem had finally closed the frontier gap with American AI leaders.
But official benchmarketing often tells a curated story. To cut through the marketing noise, we turn to independent, third-party evaluations from organizations with no stake in either ecosystem. Two recent assessments—one from the U.S. Center for AI Standards and Innovation (CAISI) and another from the analytics firm Artificial Analysis—reveal a more nuanced reality: Chinese AI has made impressive strides in efficiency and cost-performance, but a measurable capability gap remains, particularly in reasoning, agentic tasks, and parameter scale.
Here is what the data actually tells us about the state of global AI competition in 2026.
Reference 1: CAISI’s Independent Audit of DeepSeek V4
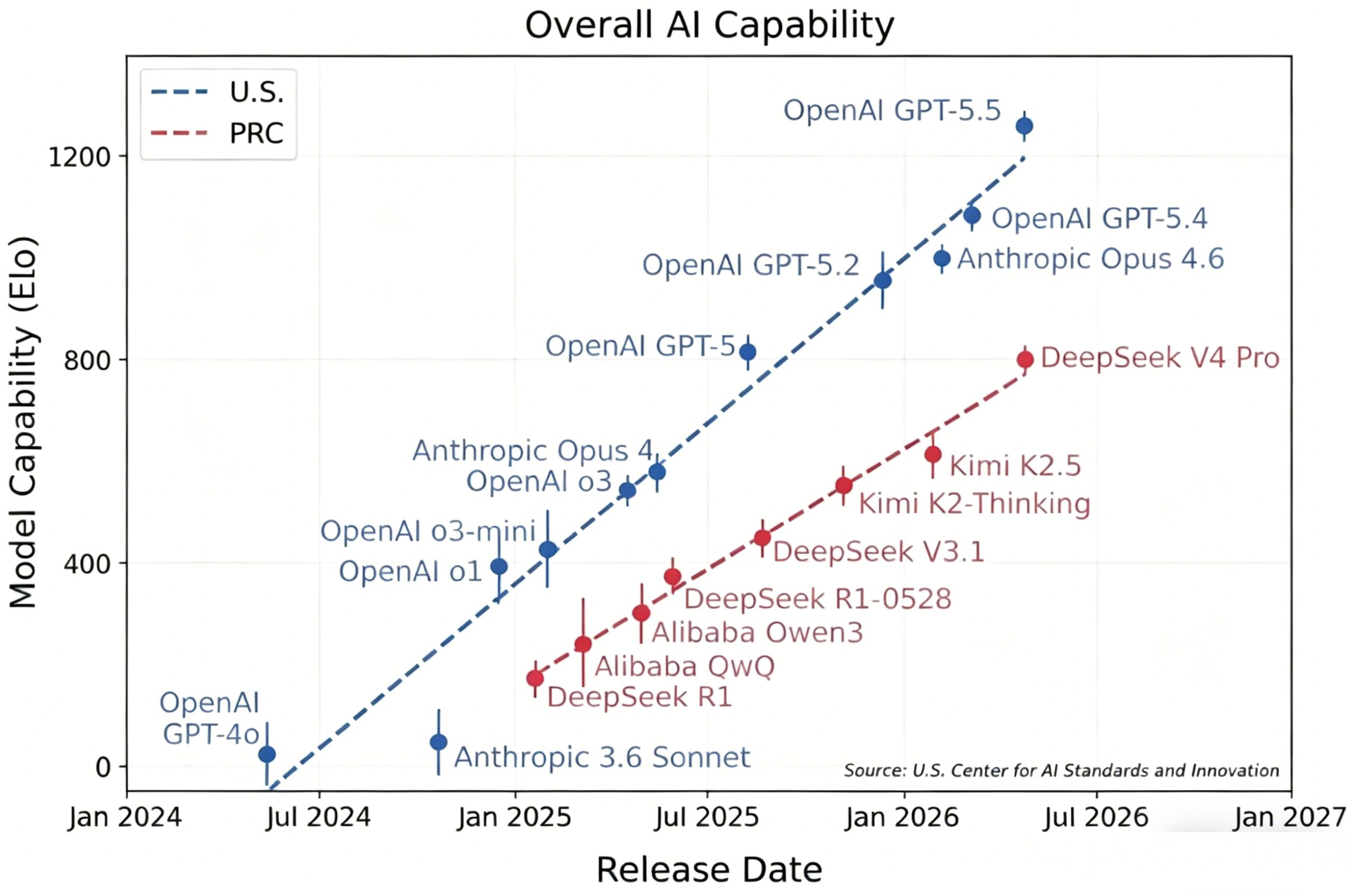
DeepSeek-V4-Pro is roughly equivalent to GPT-5, which is expected to be released in August 2025.
The Center for AI Standards and Innovation (CAISI) recently conducted one of the most rigorous independent evaluations of DeepSeek V4-Pro, testing it against OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.6. Unlike standard evaluations that rely on publicly available datasets (which may have contaminated training data), CAISI employed a mix of established and proprietary benchmarks to prevent “benchmark hacking.”
The 8-Month Lag: Capability Assessment
CAISI’s core finding was stark: DeepSeek V4-Pro represents the pinnacle of Chinese open-weight models but still trails the American frontier by approximately 8 months in overall capability.
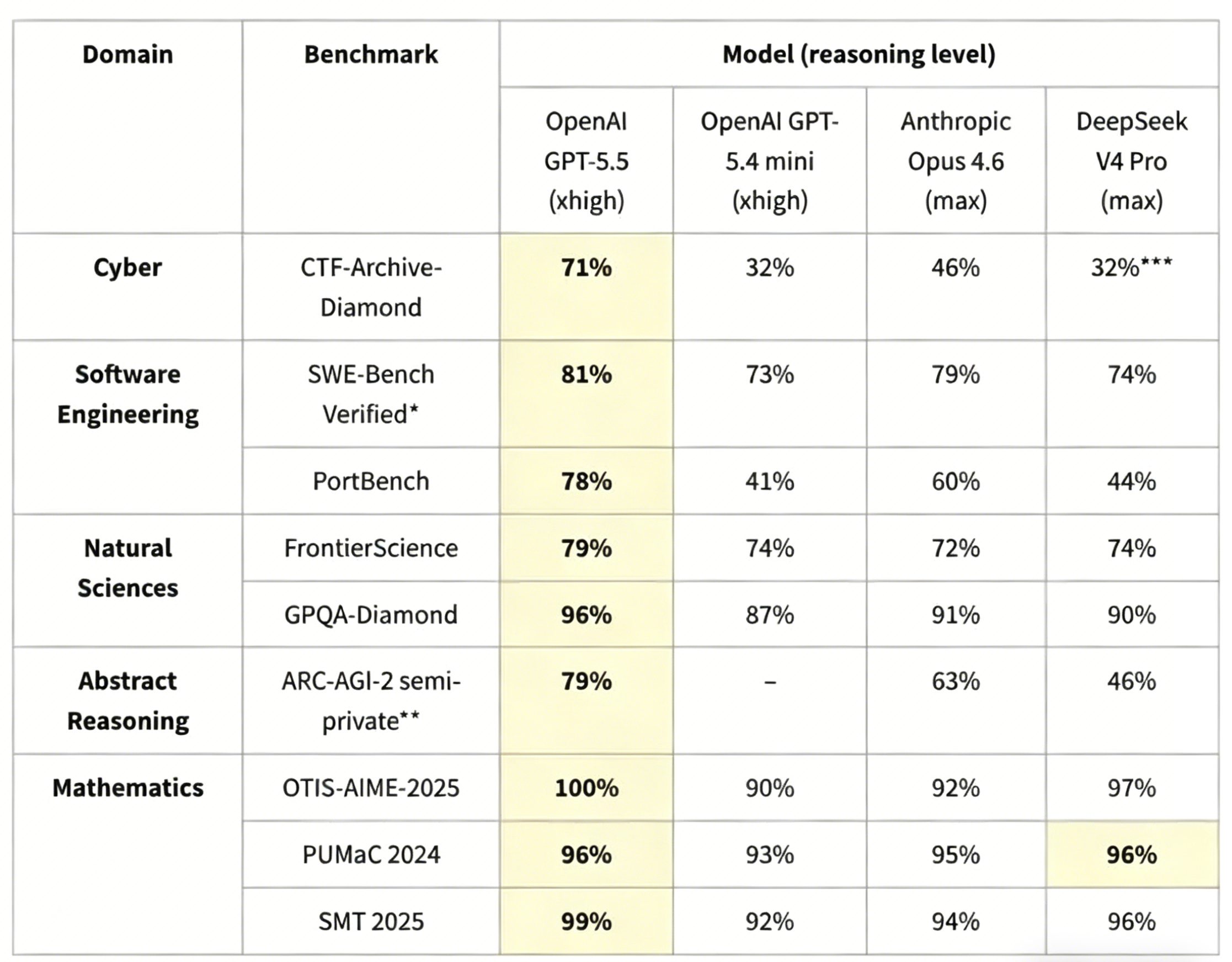
The evaluation spanned nine distinct benchmarks across five critical domains:
| Domain | Benchmarks Used | DeepSeek V4-Pro Performance vs. Frontier |
|---|---|---|
| Web Intelligence | LiveWeb Bench, CTF-Archive-Diamond | -15% to -22% behind Claude Opus 4.6 |
| Software Engineering | SWE-bench Verified, PortBench (private) | -18% on PortBench internal tasks |
| Natural Sciences | GPQA Diamond, MMLU-Pro | Near parity (-3% to -5%) |
| Abstract Reasoning | ARC-AGI-2 (semi-private) | -27% on hidden test set |
| Mathematics | AIME 2026, FrontierMath | -12% on novel problems |
Key Insight: When evaluated on DeepSeek’s publicly reported benchmarks—datasets the model was likely optimized for during training—the V4 series appeared to within 3-5% of GPT-5.4 and Claude Opus 4.6. However, CAISI’s introduction of unseen, contamination-free evaluations—particularly the semi-private ARC-AGI-2 dataset and their internal PortBench software engineering suite—widened the gap significantly.
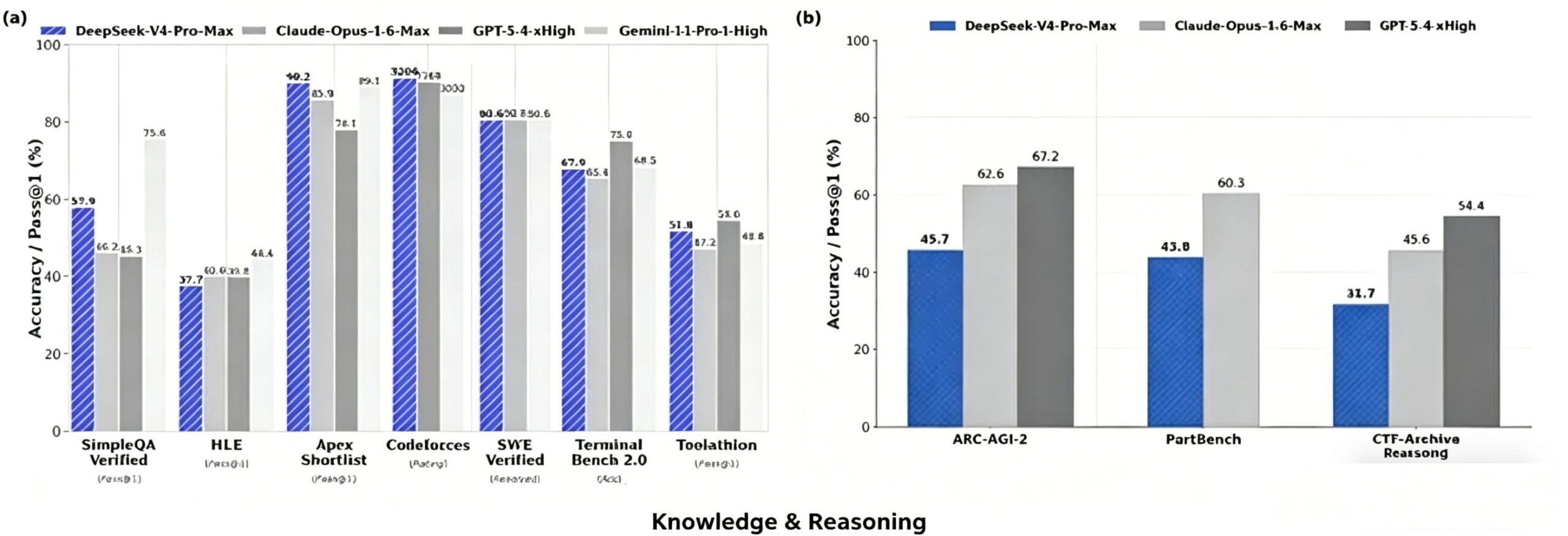
The divergence was most pronounced in agentic reasoning and cybersecurity tasks. On the CTF-Archive-Diamond benchmark (capture-the-flag cybersecurity challenges requiring multi-step tool use), DeepSeek V4-Pro exhibited brittle reasoning chains, frequently failing when required to adapt strategies mid-task or handle ambiguous instructions. GPT-5.5 and Claude Opus 4.6 maintained robust performance across task variations, suggesting superior generalization.
The Cost Revolution: Efficiency as China’s Moat
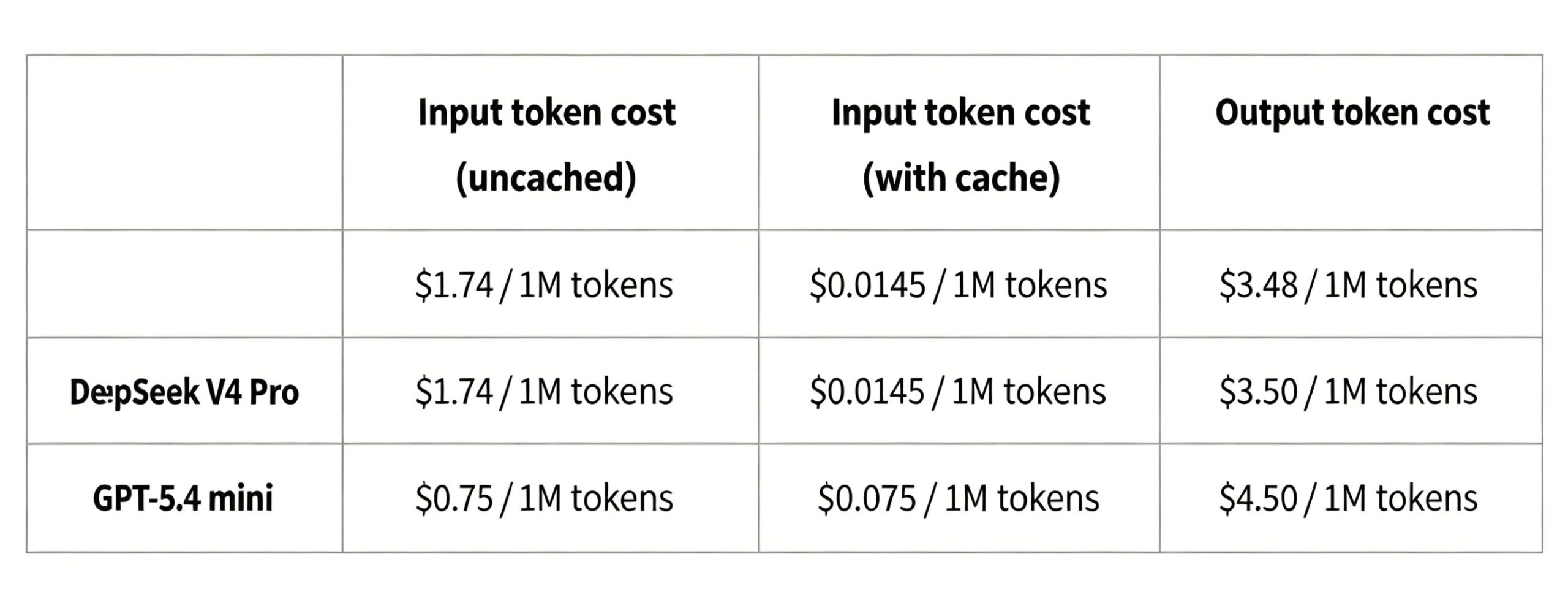
Where DeepSeek V4 truly disrupts the market is not raw capability, but inference economics. CAISI conducted a normalized cost-efficiency analysis, pairing DeepSeek V4 against OpenAI’s GPT-5.4 Mini—a model with comparable Elo ratings (749 vs. 800 on the Chatbot Arena leaderboard).
The results reveal China’s strategic advantage:
- Pricing Advantage: Across seven standard tasks, DeepSeek V4 was cheaper than GPT-5.4 Mini in five instances.
- Cost Variance: Range varied from 53% cheaper (mathematical reasoning) to 41% more expensive (long-context document analysis).
- Average Efficiency: Approximately 30% lower cost-per-query at comparable capability levels.
Critical Caveat: CAISI’s calculations used DeepSeek’s listed API pricing. With current promotional discounts and quantity pricing factored in, real-world inference costs for DeepSeek V4 drop another 20-40%, solidifying its position as the king of price-performance in the 2026 LLM market.
This efficiency stems from architectural innovations—likely mixture-of-experts (MoE) routing and aggressive quantization—allowing Chinese labs to deliver 85-90% of frontier performance at 30-50% of the operational cost.
Reference 2: Artificial Analysis Intelligence Index
While CAISI focuses on capability ceilings, the analytics firm Artificial Analysis tracks practical deployment intelligence—how models perform in real-world, latency-sensitive applications. Their Intelligence Index offers a complementary perspective on the China-US AI gap.
According to their February 2026 assessment:
- DeepSeek V4-Pro has achieved functional parity with GPT-5.2 (released December 2025) on their composite index.
- Gap Duration: Approximately 4-5 months behind the current OpenAI flagship.
This narrower gap (4-5 months vs. CAISI’s 8 months) reflects different evaluation philosophies. Artificial Analysis weights throughput, API reliability, and multilingual performance more heavily than pure reasoning benchmarks. DeepSeek V4’s architecture appears optimized for these production metrics, suggesting Chinese labs prioritize deployable utility over laboratory benchmark supremacy.
For enterprises choosing between models, this is crucial: if your use case prioritizes cost-effective, high-volume document processing or customer service automation, the practical gap may indeed feel like only 4-5 months. If you require frontier research capabilities, autonomous coding agents, or complex scientific reasoning, the lag extends closer to 8 months or more.
The Hidden Variable: Parameter Scale and the 1T Threshold
Beyond benchmarks and pricing lies a structural factor that will determine long-term competitiveness: model size. A frequently overlooked paper from late 2025, “Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity,” attempted to reverse-engineer the parameter counts of closed-source models through memorization capacity tests.
While the paper’s initial estimates (suggesting Chinese models were 3-4x smaller than American counterparts) faced methodological criticism, subsequent corrections still revealed a significant scale gap:
The Consensus View: Leading American closed-source models (GPT-5.5, Claude Opus 4.6, Gemini Ultra 4.0) likely operate in the 1.5-3 trillion parameter range (counting active parameters in MoE architectures), while China’s strongest open-weight models, including DeepSeek V4, likely remain below 1 trillion total parameters.
Why does this matter?
- Emergent capabilities in reasoning and tool use often appear abruptly as scale thresholds are crossed.
- Knowledge density—the ability to store rare facts and complex procedural knowledge—scales non-linearly with parameter count.
- Future-proofing: If the “1T parameter wall” represents a necessary but not sufficient condition for frontier capability, Chinese labs must scale up infrastructure to compete at the bleeding edge, not just optimize existing architectures.
Strategic Implications: Two Paths to AI Supremacy
The 2026 data reveals not one AI race, but two:
America’s Path: Brute-force scaling and closed-source aggregation. GPT-5.5 and Claude Opus 4.6 represent the “more parameters, more compute, more data” philosophy. The result is undeniable capability leadership, but at staggering training and inference costs.
China’s Path: Architectural efficiency and open-weight distribution. DeepSeek V4 demonstrates that through clever routing algorithms, quantization, and training data curation, 85% of frontier capability can be delivered at 20% of the cost. This strategy wins the democratization war—more developers globally can afford to build on DeepSeek than on OpenAI.
However, the capability ceiling remains American territory. For applications requiring autonomous scientific research, advanced cybersecurity operations, or complex multi-agent workflows, the 8-month gap is qualitative, not just quantitative.
As of May 2026, the narrative of “China has caught up” is partially true but dangerously incomplete. DeepSeek V4 is the most capable open-weight model ever released, offering unprecedented price-performance that is reshaping global AI economics. For startups and cost-conscious enterprises, it is often the rational choice over GPT-5.5.
Yet the frontier gap remains real and measurable—8 months in pure reasoning, 4-5 months in production utility, and potentially wider in agentic autonomy. Until Chinese labs match the parameter scale and training compute of OpenAI and Anthropic, a ceiling exists on the complexity of tasks their models can reliably perform.
For now, we live in a bifurcated world: American models lead on the bleeding edge, while Chinese models dominate on the balance sheet. For most users, that is good enough. For the future of artificial general intelligence, the race is still OpenAI’s to lose.